 ABSTRACT
ABSTRACT
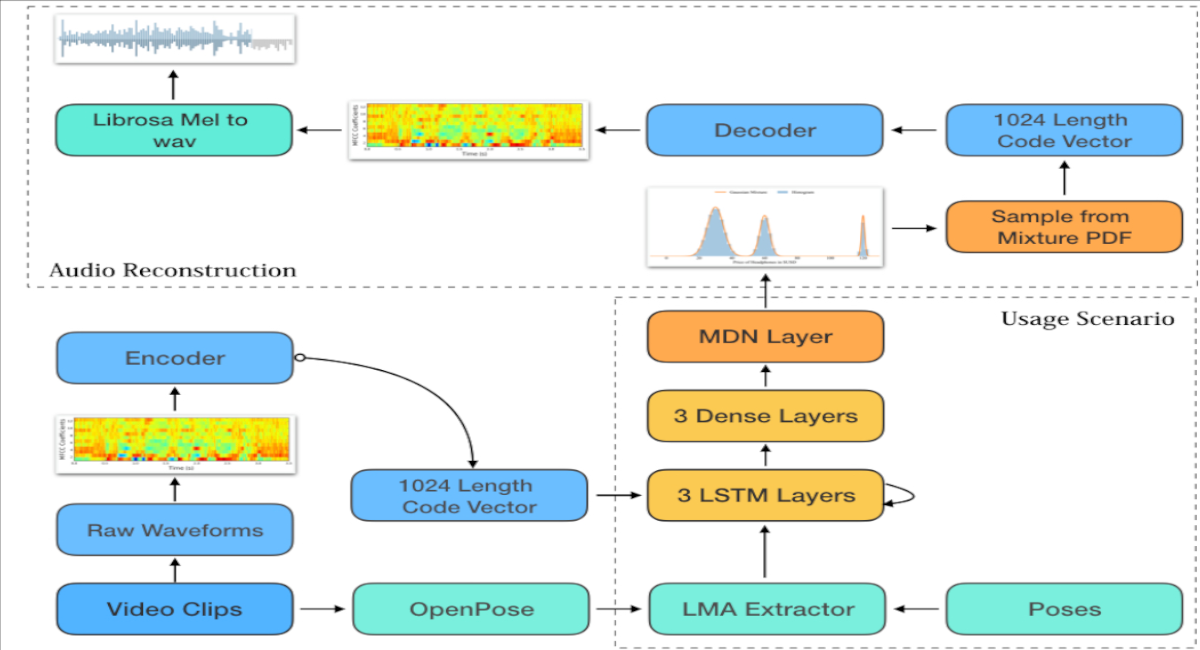
This paper describes ASDF-RNN (Audio Synthesis from Dance Features), a neural network architecture for synthesising raw audio directly from motion features extracted with a computational model based on Laban Movement Analysis (LMA). The system is composed of a deep recurrent Neural Network that maps LMA features to a mixed gaussian distribution of encoded mel-spectrograms representing classical music. Audio is reconstructed by sampling from the mixed gaussian distribution and decompressing the mel-spectrogram with a dedicated decoder network trained on classical music. The results from this investigation are promising, however the generated audio retains very little resemblance to its original source. Additionally, an informal qualitative assessment made it clear that audio generated by ASDF-RNN from widely different motion had no perceivable differences in melody or harmonic content.