ABSTRACT
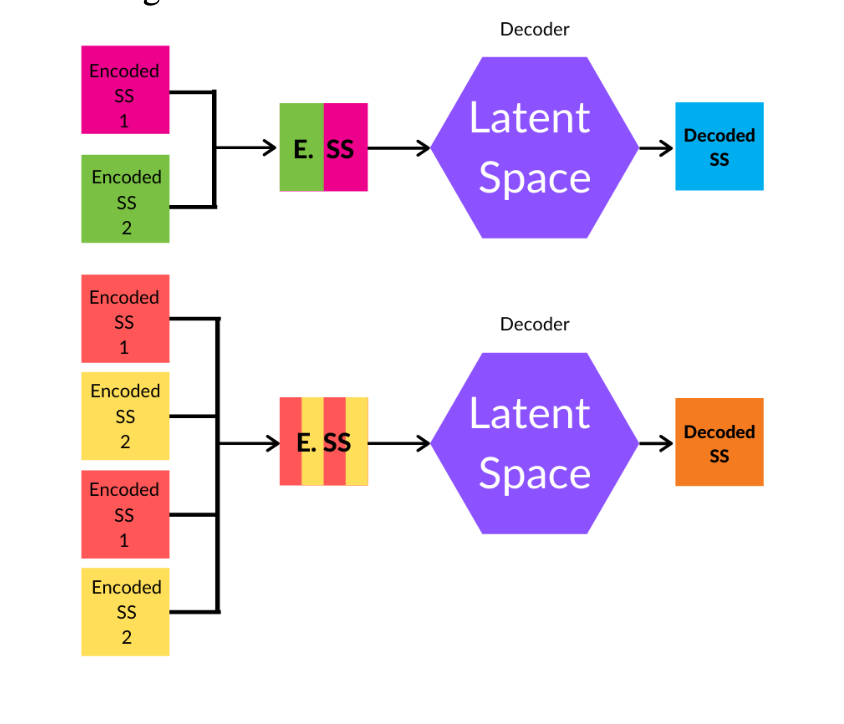
Audio generation has been addressed in many ways with the focus to reproduce hours of a music style or specific voice inter alia [1][2]. However, little has been done to actually resemble a song within its characteristic content structure. We can highlight some attempt [3] but it is a constraint song generation as it needs some input/guideline from a user. The Song Machine (TSM henceforth) tries to reproduce a whole song which sound resembles the one by a particular music band following two different approaches: audio and midi. It works on the song sections of the band song dataset to extract its features to build up a new song. Our study is unique differing from other researches as it focuses on song sections (chorus, bridge, intro...) rather than only the whole song as we want to reproduce a song with a certain structure elements that repeat over time.